Всем-всем привет!
С самого своего создания поисковые системы двигались на встречу обычным пользователям, ищущим ответ на свой вопрос на просторах Интернета. Движение это сопровождается постоянными экспериментами, внедрением новых алгоритмов и прочих вещей, что, в свою очередь, приводит к неработоспособности одной за другой методик . Да-да, цель ПС – убить SEO окончательно!
Для подтверждения всего вышесказанного упомяну всем известные Яндекс и “Минусинск”: первый чистит SERP (топ поисковой выдачи), да и всю выдачу, от некачественных и переоптимизированных текстов, а второй борется с . Если еще пару лет назад можно было спокойно попасть в ТОП-10 накупив ссылки в , или в любом другом агрегаторе, то сейчас уже приходится подходить к этому делу с особой осторожностью. То же самое можно сказать и про .
Но ведь оптимизаторы не дураки – постоянно находят выходы из непростых ситуаций. Примером может послужить LSI-копирайтинг, о чем я и хочу Вам сегодня рассказать. Погнали!
Что такое LSI-копирайтинг?
LSI-копирайтинг – методика написания текстов, построенная на смысловой направленности. Если тематику в SEO-текстах можно определить по наличию определенных ключевых слов, то в LSI-текстах тематика определяется на основе смысловой связи слов.
Чтобы было проще понять:
Если в тексте встречаются слова “объектив”, “фотография”, “матрица”, “баланс белого”, “фокус”, “мыльница”, то текст скорее всего о фотоаппарате.
То есть, в ЛСИ-копирайтинге упор делается не столько на ключевые слова, хотя их тоже нужно использовать, но делать это надо так, чтобы они четко вписывались в текст и не выделялись, сколько на взаимосвязь используемых слов. Тут уже не решает плотность “ключей”, тут решает то, как слова соответствуют контексту материала.
Бывают даже случаи, что статья выходит в ТОП-3 по определенному запросу, хотя его в ней нет. Поисковые системы научились понимать смысл текста, на что и делается упор.
Как появился LSI-копирайтинг?
Не будем лезть в дебри формирования поисковых алгоритмов, пройдемся поверхностно.
Как уже было сказано, поисковые машины научились понимать смысл текста, что и подтолкнуло на создание текстов по методике LSI. Первый толчок случился в 2011-м году, когда в Google внедрили серьезный алгоритм под названием Panda, задачей которого является борьба с некачественными текстами, да и вообще с некачественными страницами с точки зрения удобства взаимодействия с ними пользователей.
Затем, спустя два года, тобиш в 2013, появляется алгоритм Колибри, призванный оценивать полноту ответа на запросы пользователей и, как следствие, смысл текста, выводя в выдаче сайты с наиболее раскрытым ответом. С внедрения этого алгоритма и началась история LSI-копирайтинга, как метода продвижения сайта.
Вот уже 4 года Google старается работать со смыслом текста, а не с ключевыми словами.
Как писать LSI-тексты?
Четких критериев для LSI статьи нет, ведь главный и основополагающий принцип – дать полный ответ на запрос пользователя. Однако можно выделить несколько пунктов, которые важно учитывать при написании текстов подобного рода:
- Необходимо употреблять в статье большое количество тематических слов. Благодаря этому, ПС поймут к какой тематике относится статья и на какой вопрос пользователя ответит;
- Необходимо полностью раскрывать суть проблемы, иначе “поисковики” сочтут материал не полным, следовательно, ранжироваться он будет ниже;
- Наличие четкой и удобной структуры текста;
- Информация, изложенная в материале, должна быть максимально достоверной;
- Также следует показывать свою экспертность по данной в статье тематике.
Соблюдая все вышеперечисленные требования, можно составить вполне себе годный LSI-текст. Главное – дать посетителю то, что он искал, в максимально полной форме.
Конечно, использование ключевых слов никто не отменял, ведь так или иначе они являются основной частью продвижения в поисковых системах. В LSI использование поисковых запросов необходимо для более широкого ответа, поэтому важно использовать не только основные запросы (), но и дополнительные. Собрать дополнительные фразы можно из:
Проработав все эти источники дополнительных поисковых запросов, можно собрать достаточно широкое семантическое ядро для LSI-текста. Тем самым Вы сможете сделать свою статью достаточно качественной с точки зрения ЛСИ и поможете поисковикам легче воспринимать ее.
Коли поднятая в этом уроке тема затрагивает работу именно со смыслом текста, то неплохо было бы привести пару примеров, объясняющих всю ее суть:
Текст №1. Все места на трибунах заняты. Судья с футбольным мячом выходит на поле вместе с игроками двух команд – Барселоны и Реала. Матч вот-вот начнется…;
Текст №2. Сегодня посещаемость бьет все рекорды. Нас ждет великолепное зрелище, которое запомнится всем надолго…
Вышеприведенные примеры я писал на одну и ту же тему – футбольный матч. Как Вы думаете, какой текст будет ранжироваться выше? Конечно же, первый, так как в нем употреблено бОльшее количество слов/словосочетаний, связанных с футбольной тематикой и в частности с “Эль-Классико” (матч между Барсой и Реалом). Во втором же тематика полностью размыта, от чего понять о чем он человеку и роботу будет слишком тяжело.
То есть, чем больше в Вашем материале будет тематических или околотематических фраз, тем легче будет поисковой машине понять тематику и, как следствие, Ваши позиции будут выше.
Подводя итог, можно сказать, что LSI-копирайтинг раздвигает те рамки, в которые нас поставили SEO-тексты, теперь есть место для творчества. Главное – дать полный ответ пользователю на его вопрос.
Ну а на этом все, дорогие друзья!
В следующих уроках разберем технические нюансы текстов подобного вида, поэтому подписывайтесь на обновления блога, если Вы этого еще не сделали.
До скорых встреч!
Предыдущая статьяСледующая статья
Многих начинающих, и довольно опытных копирайтеров интересует, что такое LSI-копирайтинг. Это словосочетание пугает многих. Можно пугаться сколько угодно, но новые веяния приходят в нашу жизнь, не спрашивая разрешения. Сегодня мы поговорим о том, что за дикий зверь скрывается под этим названием. Почему нужно знать основы LSI, а также, как такое знание поможет в работе человека, создающего контент. Тут стоит отметить, что статья будет менее полезна чистым продажникам, так как им редко требуется скрещивать крокодила и жирафа, делая текст продающим и подходящим под требования поисковиков.
Что такое LSI-копирайтинг? Для начала давайте разберемся с основным термином, что он значит. Под LSI подразумевают скрытое лингвистическое индексирование. Иногда его называют еще и тайным. При таком методе определения релевантности страницы учитываются не только основные ключевые слова, но и синонимы, а также связанные с ними словосочетания. Далее мы попробуем разобраться, как это можно использовать в практике копирайтера.
Как это работает
Современные алгоритмы являются самообучающимися машинами. У Яндекса это пресловутый Матрикснет. Благодаря заложенному принципу нейронной сети, система способна определять релевантные запросу тексты по наличию сопутствующих слов на странице. На практике, это выглядит как вывод на первые строчки статьи об автомобилях, где встречаются слова:
Автомобиль;
Машина;
Транспортное средство.
И задвигание вглубь страниц, где в статье о кошках вписан ключ «купить автомобиль».
Таким образом, удаляются из поиска статьи о белых медведях с ключом «купить мужские часы» (пример из реального ТЗ). Постепенно выдача очищается от всякого хлама. Пользователю проще выбирать релевантную его потребностям информацию.
На практике, это можно посмотреть в анализаторах от Google, а также во многих программах по анализу сайтов. Там в обязательном порядке указывается . В него входят наиболее часто встречающиеся на ресурсе слова. Соответственно, получают преференции те сайты, которые имеют большее количество упоминаний основного ключевого слова, а также производных от него.
Подбор ключевых слов
Как не крути, а LSI все же является разновидностью оптимизации . Поэтому, от подбора ключевых слов тут никуда не денешься. Самым простым способом является проверка с помощью сервиса Вордстат от Яндекса. В этом случае после того, как вы подберете ключевое слово, следует обратить внимание на колонку «с этим запросом искали». Вот это и есть синонимичные выражения с точки зрения Яндекса. Но, тут нужно смотреть на действительное соответствие основного ключа и вспомогательных.
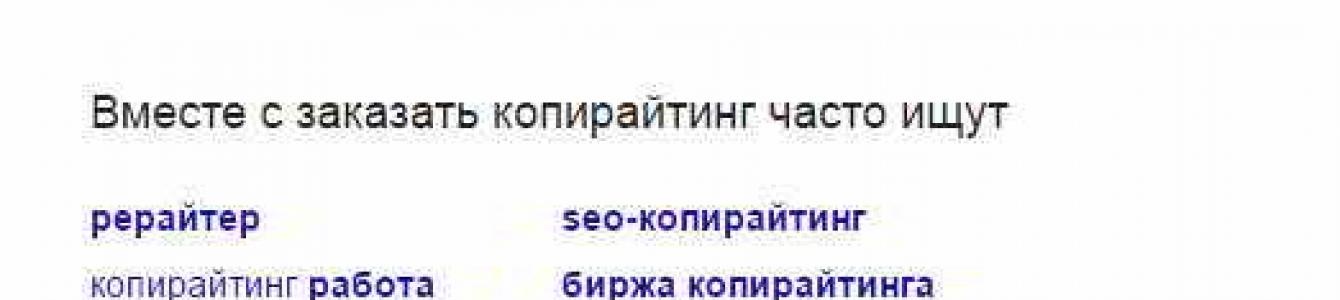
Другой, не менее простой способ, это использование поиска от Google. Для этого вбиваем в поисковую строку наш основной ключ. Допустим, это будет «заказать копирайтинг». Далее смотрим внизу страницы выдачи вариации запросов, которые люди задают вместе с основным вариантом. В моем случае получилось вот так.
Именно это и является семантическим облаком, вокруг которого следует плясать при написании LSI-текста.
Еще один не менее интересный сервис для подбора облака ключевых слов — Ubersuggest tool. Тут список слов более широкий, все слова расположены в блоках. На скриншоте можно увидеть основной блок из этого сервиса, проверка выполнялась по слову «копирайтинг».
Вот так, с помощью довольно простых инструментов можно определить семантическое облако.
Пишем текст
Сейчас, довольно часто копирайтеры возмущаются некоторыми ТЗ с большим количеством однословных ключей, которые нужно вписать в текст. Также там обычно дается пул из 2-4 слов, которые должны иметь максимальную частотность в тексте. На выходе получается LSI-текст. Ниже я рассмотрю основные аспекты написания подобных статей.
Довольно часто копирайтеры получают заказы с большим количеством ключей. Причем все эти ключи односложные. Выглядеть список ключей может примерно вот так.
Тут я показал, как может выглядеть фрагмент ТЗ. Но, это не обязательно. В некоторых случаях просто предлагается перечисление через запятую. А теперь ловите первый лайфхак. Если вам предложено большое количество ключей, и все они должны упоминаться по нескольку раз, то просто скопируйте список в рабочий файл ниже текста, и оттуда уже вставляйте ключи в статью. Это позволит гарантированно вписать все ключи в текст, это проще, чем после написания заниматься подсчетом.
Теперь переходим к особенностям вписывания подобных ключевиков в статью.
Основное правило: слова должны распределяться равномерно по тексту.
Конечно, не нужно высчитывать расстояние между двумя словами, но старайтесь не сгруппировывать их в одном месте. Это не очень нравится поисковикам, да и для людей такой текст окажется не слишком читабельным. Наверно, вам будет интересно, можно ли изменять слова при вписывании. По моему мнению, морфологические вхождения допустимы. Для поискового бота нет разницы между «автомобиля» и «автомобилю». Он понимает оба варианта. Но, на практике все будет зависеть от вашего заказчика, стоит обсудить этот вопрос с ним.
Проверка
Не менее важным моментом в написании LSI-статьи, является проверка соответствия тексту. Тут можно посоветовать несколько сервисов. Первый из них . В нем следует смотреть на процент тошноты по слову. Максимальный показатель не более 3,5%. Лучше уложиться в 3%. Как пользоваться этим инструментом я писал ранее.
Другой инструмент – Истио. Принцип действия схож с анализатором от Адвего, но тут имеется полезная фишка. В специальное поле можно внести ключевые слова, а сервис их посчитает, а также подсветит их расположение. Так можно легко определить место расположения каждого, и при необходимости разнести на большее расстояние.
Напоследок
Поисковые системы постоянно развиваются, но оптимизаторы и копирайтеры не очень торопятся следовать нововведениям. Поэтому, вопрос, что такое LSI-копирайтинг до сих пор не является редким. На самом деле, тут нет ничего сложного, отличие от стандартных SEO-полотен в особенностях подбора и расположения ключей. Надеюсь, что эта статья натолкнет вас на мысль изучить новое направление в копирайтинге. Не забывайте делиться с друзьями, а также задавать вопросы в комментариях.
Несколько лет назад активно тиражировались новости о том, что поисковые системы научились думать. Это заключалось в понимании информации, которая находится на странице. Последние 2 года в Рунете постоянно поднимается тема LSI-копирайтинга. Пришло время и нам поговорить о нем.
Зачем нужен LSI-копирайтинг, что это и почему SEO-копирайтинг умрет через время - разберем в этой статье.
Для начала, что же такое LSI? Латентно-семантическое индексирование (Latent Semantic Indexing) - алгоритм поисковых систем, с помощью которого они анализируют страницы сайта не только на наличие ключевых слов, но и на синонимы, которые связаны с ключами.
Достаточно значимым примером можно привести слово «metro». Есть несколько значений.
- Metro - метрополитен
- Metro - компания
- Metro - книга
- Metro - игра
В каждом случае поисковая система распознает по словам и фразам свой контекст . И при поиске, к примеру, фразы «подземка Москвы» будут отфильтрованы нерелевантные запросы, описанные выше, которые не касаются метрополитена.
Почему о LSI-копирайтинге говорят все больше?
Достаточно проанализировать действия поисковых систем, чтобы стало понятно, в какую сторону идет их движение. Алгоритмы Panda и Hummingbird показали насколько важен хороший контент на сайтах . Аналогично у Яндекса есть фильтр АГС.
Помимо этого, интересные вещи происходят в Google Analytics и Яндекс.Метрики. Поисковые системы все меньше заинтересованы в показе ключевых фраз , по которым пользователи переходят на сайт.
Но самое главное в третьем факторе. По заявлениям представителей поисковых систем, их пользователи все больше используют для поиска разговорные форматы фраз , а не шаблонные ключи. Под эти фразы далеко не всегда можно оптимизировать контент, но понимание поисковыми системами заданной поисковой фразы позволяет предложить максимально точную выдачу.
Все это позволяет нарисовать картину недалекого будущего, где LSI-копирайтинг полностью заменит собой SEO-копирайтинг . Важно понимать, что в Рунете это будет происходить достаточно долго. Есть несколько причин для этого.
- Оптимизаторы ориентируются на Яндекс и пока его изменения не станут значимыми, ничего не изменится
- Рынок SEO-специалистов достаточно инертен , поэтому переход большинства займет длительное время
- Многие не смогут разобраться в отличиях SEO-копирайтинга и LSI-копирайтинга
Какая разница между SEO- и LSI-копирайтингом?
Что из себя представляет написание SEO-текста?
- Ключ, по которому происходит продвижение
- Дополнительные ключи
- Название статьи
- Тошнота текста
- Уникальность
Это если кратко. Одним из основных параметров является количество использования ключевых фраз и их форма (точное или разбавочное вхождение).
В случае с LSI-копирайтингом сохранится общая суть, но работа с ключами преобразится . В первую очередь делается упор на синонимы и контекст. Это сыграет на руку тем сайтам, которые вкладываются в хороший контент. Необходимо будет собирать максимальное количество синонимов, которые подходят под нужные ключи и вписывать их в текст.
Важно понимать, в хорошем тексте по-любому будут присутствовать синонимы главного ключа. Если их нет - текст плохо написан. Повысятся требования к текстам по уровню качества , а самые упертые SEO’шники будут предоставлять авторам список синонимов, которые необходимо использовать. Грубо говоря, появится большее количество ключевых слов для текста.
Может показаться, что SEO останется на месте, просто «закрутят сильнее гайки». Но поисковые системы надавят на оптимизаторов еще круче, чем кажется. Все дело в том количестве оптимизаторов, которые продолжат заниматься SEO по старинке. Естественно, они будут не успешны.
А те, кто перейдут на новую модель, получат все лавры. Главное понимать, что ничего плохого в оптимизаторах нет, если они используют «белые» методы и только помогают улучшать выдачу. Тексты станут лучше , а посетители будут довольны. Авторский контент может ослабеть по отношению к продвигаемым гигантам, но даже сейчас основные топ-позиции занимают далеко не любительские сайты.

SEO-копирайтинг уходит в прошлое?
Почти. Он видоизменяется. Пока более-менее активно данный процесс двигает Google , но в скором времени этим плотно начнет заниматься и Яндекс. Сам SEO-копирайтинг может остаться как термин , но поменяет свои правила на LSI-копирайтинг. Здесь будет играть роль маркетинг от крупных SEO-студий.
Если LSI-копирайтинг не приживется, это не значит, что рынок не использует его. Рано или поздно все перейдут на него , вопрос в том, как это будет называться. SEO-оптимизация - огромный бизнес и в зависимости от интересов самых сильных игроков LSI-копирайтинг может появиться, а может и нет.
Есть еще мнение, что каждый хороший текст уже сейчас является LSI-копирайтингом. Так ли это? Не совсем. Любой текст даже сейчас может оказаться сделанным по правилам LSI-копирайтинга, но общая тенденция к этому не относится.
Основной уклон должен делаться на синонимы. Остаются общие ключи, но для успешного продвижения и активного роста позиций придется дополнительно разбираться с синонимами . Это все даст свой эффект и позволит наращивать количество переходов.
Еще важный момент про ссылки в статьях. SEO-оптимизаторы часто вставляют ссылки на разные страницы/сайты, которые плохо относятся к теме статьи. Поисковые системы все лучше понимают, что ссылка с анкором про самолеты в статье про оливье лишняя. Со всеми вытекающими последствиями.
Все вышеописанное приводит к одному тезису - поисковые системы хотят улучшить выдачу и убрать из нее наименее полезные сайты . Все, как и всегда. Контент - король , и все в этом духе. Если вы сомневаетесь в необходимости использования контент-маркетинга для своего проекта, пришло время пересмотреть это решение.
А что вы думаете насчет LSI-копирайтинга?
Писать тексты для интернета становится сложнее. Борцы за первые места в выдаче поисковых систем ищут все новые и новые чудодейственные средства: «Снижать тошноту!», «Повышать уникальность!», «Больше ключей!», «Меньше ключей!» и уж совсем загадочное заклинание - LSI-копирайтинг. Разберемся, что это на самом деле такое и стоит ли отказываться, если вас просят написать LSI-текст.
Окунёмся в историю
Первый способ избавиться от страха перед чем либо - понять, что это такое.
За аббревиатурой LSI скрываются первые буквы термина latent semantic indexing, который можно перевести с английского, как латентное семантическое индексирование. Но это лишь первая мартёшка, которая скрывает в себе ещё одну аббревиатуру - LSA, произошедшую от термина latent semantic analysis (латентно семантический анализ). Думаю, для первого абзаца достаточно сложных слов, которые пора бы и объяснить.
Итак, метод LSA известен ещё с 1988 года. Изначально его использовали для анализа баз знаний, чтобы автоматически построить структуру большого числа документов и выявить взаимосвязи между ними. Не будем углубляться в механизм работы LSA, желающие могут с ним ознакомиться самостоятельно. Нам важно только то, что латентно-семантический анализ позволил находить сходные по содержанию документы, исходя из используемых в них слов. Иногда речь даже шла о машинном «понимании смысла текста».
Конечно же, такой метод не могла обойти вниманием компания, ежедневно анализирующая миллионы текстов. Поисковый гигант Google начал делать первые намёки на использование чего-то подобного в 2011 году, после релиза алгоритма «Панда» . Год спустя возник термин LSI-копирайтинг . А в 2013 году миру был представлен алгоритм «Колибри» , который, по заявлениям Google, анализировал смысл документов.
Сразу после этого пошли разговоры о том, что SEO совсем скоро перестанет работать и всем нужно срочно осваивать LSI-копирайтинг.
LSI-копирайтинг против SEO-копирайтинга
Напомню, как работает SEO-копирайтинг: составляем семантическое ядро - список ключевых слов, которые наиболее точно описывают смысл статьи и вписываем слова в текст.
В этом случае мы исходим из того, что поисковая система сравнивает запрос пользователя с текстом, и если находит в нём ключевые слова, считает, что этот текст соответствует запросу. Очевидно, что такая модель имеет недостатки.
Например, она позволяет вставлять в текст ключевые слова, никак не связанные по смыслу с основным содержанием статьи. Несколько лет назад можно было встретить в интернете кучу статей, в середине которых была вписана ссылка с совершенно неожиданным текстом. К примеру, в рецепте жарки мяса обнаруживалась ссылка на покупку деталей для автомобиля.
Сейчас это уже невозможно, потому что поисковые системы научились отсекать такие смысловые несоответствия. Достигается это с помощью технологий, основанных на использовании LSA. То есть поисковики анализируют не только наличие в тексте статьи слов из запроса пользователя, но и обращают внимание на синонимы, родственные по смыслу слова и термины, часто употребляемые в материалах сходной тематики.
Например, в статье про ремонт автомобилей, помимо слов «ремонт» и «автомобиль» должны быть слова «машина, детали, техобслуживание, запчасти» и так далее. Если этих слов нет, то и статья уже не будет высоко ранжироваться в указанной тематике.
Отсюда становится очевидным принцип LSI-копирайтинга: использовать не только точные вхождения ключевых слов, но ещё их синонимы, родственные и близкие по смыслу слова, а также термины, характерные для текстов сходных тематик. Кстати, подобрать эти слова можно в сервисах подбора слов Яндекса и Google.
Ищем идеальную формулу
Для статей, объемом более 3000 знаков с пробелами плотность LSI-слов должна быть не меньше 100 штук на каждую 1000 слов текста. Для статей меньшего объема плотность нужно уменьшить до 30 LSI-слов на каждую 1000. В заголовок, HTML тег title, желательно вписать как минимум 5 LSI-слов. Желательно использовать LSI-слова в каждом предложении текста.
Есть и другие, менее конкретные рекомендации:
- Стараться в статье наиболее полно раскрыть суть проблемы.
- Структурировать текст для более удобного чтения.
- Проверять все факты, используемые в тексте.
- Показывать свою экспертность.
Считается, что такой текст для поисковой системы будет более релевантным, а следовательно, ранжировать она его будет выше других.
LSI-копирайтинг не панацея
Как у любой технологии, у LSI тоже есть недостатки.
Метод не учитывает взаимосвязи между словами и их порядок. Это значит, что бессвязный набор соответствующих терминов может быть «оценён» поисковой машиной выше связного текста.
Система не учитывает многозначность слов. Смысл тексту могут придавать не только слова-маркеры, характерные для тематики, но и образные выражения, метафоры, сравнения. Всё это снова оказывается за пределами «машинного понимания».
Если текст посвящен одновременно двум разным темам, то система выберет из них только одну, а по второй позиций этот текст не получит.
Создаём интуитивный LSI-копирайтинг
На первый взгляд может показаться, что LSI-копирайтинг - это то же SEO, только с гораздо большим количеством ключевых слов. Вместо 5–6 словосочетаний, наиболее полно описывающих тему статьи, вам придется вписывать в текст 15–20 слов. И это не может не пугать, потому что подразумевает куда больший объём работы.
Но задумаемся на минутку: что такое хорошая статья? Это интересный читателю текст, который отвечает на его вопросы, полностью раскрывает тему. Чтобы такую статью написать, автору нужно изучить фактический материал, структурировать его, подать в .
Но главное, если вы будете писать статью не «под ключи», как это делают плохие SEO-копирайтеры, а действительно , то вы волей-неволей будете использовать в тексте и ключевые слова, и родственные им, и связанные по смыслу, и характерные для других текстов такой тематики. Глубоко проработанная статья - уже сама по себе будет LSI-текстом.
Так что, если вам придёт заказ на LSI-копирайтинг, не пугайтесь. Просто пишите .
Уже год как он функционирует. Теперь тексты нужно писать для людей, с синонимичными фразами ключевых запросов. Вроде все легко, но когда дело доходит до брифа на копирайтинг, появляются вопросы: где искать эти lsi фразы и синонимы? сколько должно быть синонимов? сколько должно быть lsi фраз? как правильно их выбрать?
Простыми словами что такое LSI слова или фразы — это те слова и фразы, которые задают тематику нашего ключевого запроса и чаще всего используются вместе с ним в тексте.
Перейдем к небольшой инструкции:
Поиск и подбор слов для lsi-текста
Все также как раньше нам нужен ключевой запрос — берем его из . А дальше нам нужно отобрать часто упоминающиеся слова и фразы с этим ключевым запросом. Где их брать?
Вводим запрос в поисковую систему, смотрим подсказки и рекомендации — выписываем
Рис.1 Подсказки

Процесс становится трудоемким если вы собираете LSI слова сразу для большого количества запросов, в этих случаях помогают сервисы с парсерами подсказок и рекомендаций.
Yandex Wordstat
Смотрим правую колонку, выписываем то, что не попало в подсказках и рекомендациях

После того как мы выписали все слова, которые могли быть как синонимами, так и lsi фразами из подсказок, рекомендаций и вордстата, нам нужно понять какие стоит использовать, а от каких избавиться.
Отбираем и чистим найденные lsi слова
Для начала очистить слова нужно по 2 критериям:
- По смыслу . Пример: на рисунке 2 мы видим что есть фразы которые не отвечают основному запросу нашей страницы «Баскетбольные кроссовки», а именно — волейбольные кроссовки, баскетбольные мячи, их убираем.
- По региональности и геозависимости.
После того как мы очистили список по 2м простым критериям, понять какие слова подходят по смыслу нам так же помогут конкуренты
Анализируем тексты конкурентов из топ 20
Для начала смотрим на наш КЗ и определяем коммерческий он или информационный, в нашем случае он скорее общий, но чаще всего подразумевается что пользователь собирается купить «баскетбольные кроссовки».
Поэтому если запрос коммерческий — ищем продающие страницы и карточки товаров конкурентов, если информационный, то обращаем внимание только на страницы блогов и страницы, носящие информационный характер.
Смысл отбора слов состоит в том, чтобы понять, как часто одни и те же слова или фразы встречаются на разных страницах в топ 20 по заданному КЗ.
Проще всего реализовать данный план можно с помощью текстовых анализаторов. Например всем известный текстру.

Рис..4 Анализ seo текстов
Алгоритм отбора LSI слов из текстов на страницах конкурентов
- Открываем все коммерческие страницы в браузере
- Копируем из них текст и вставляем в анализатор текста
- Смотрим, какие слова встречаются чаще всех (рис.4 и из групп и просто по частоте)
- Выписываем словосочетания и количество повторений
Фразы и слова, которые чаще всего повторяются с нашим запросом «баскетбольные кроссовки» на страницах конкурентов и фразы из подсказок и вордстата, и есть те которые мы искали, по-другому их иногда называют «фразы задающие тематику».
Теперь осталось просто сравнить какие слова и фразы чаще всего повторяются и использовать их в тексте.
Теперь к конкретике и цифрам
Основным критерием к составлению текста остается его читабельность и адекватность . Поэтому стоит выбрать не seo копирайтера, а более продвинутого специалиста.
- Используйте КЗ, синонимы, и lsi-фразы в заголовках h1-h6, в title и в description.
- КЗ используйте в начале текста 1-2 раза, далее словоформы и синонимы, в зависимости от количества найденных lsi фраз.
- Используйте маркированные и нумерованные списки
- Выберите длину текста в зависимости от количества найденных LSI слов. На 1000 уникальных слов нужно 100lsi слов, можно и больше: 100-150, главное не переусердствовать.
- Водность — 25-35%. Старайтесь избегать слов не несущих смысловой нагрузки.
- Тошнота 4-5% на 3000 знаков. Попробуйте избавиться от частых повторений КЗ в тексте, используйте синонимы
Подведем итог:
Правильно составленные LSI тексты принесут Вашему сайту ощутимые плюсы:
- Во-первых, тексты помогут избавиться от Баден-Бадена или не попасть под другие санкции Яндекса и Гугла связанные с копирайтингом.
- Во-вторых, если соблюдать вышеупомянутые критерии к написанию текстов — тексты станут адекватными и читабельными, что приведет к улучшению поведенческих факторов ранжирования.
Вас настиг Баден-Баден? Или хотите избежать санкций поисковых систем? Закажите у нас seo-аудит и мы поможем Вам с оптимизацией контента на Вашем сайте.
Подпишись и следи за выходом новых статей в нашем
Криптовалюта
Что означает слово ликвидность
Недвижимость

Что взамен мдс 81 37.2004. Указания. Состав и характеристика сборников федеральных единичных расценок на монтажные работы
Бизнес-идеи